PostgreSQL 13 Streaming Replication on Ubuntu
Introduction
In some previous post I showed you how to install PostgreSQL 13 on an Ubuntu machine, on AWS EC2 Instance. The instructions have been tested on EC2, but you can install PostgreSQL using the same instructions on any Ubuntu, or Debian Linux Server.
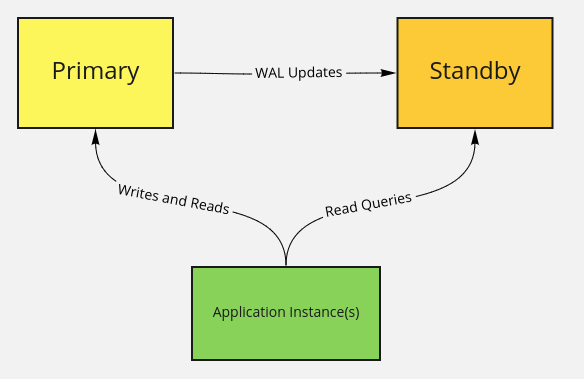
In this post, I want to show you how to setup another read-replica, or a Hot-Standby Server using Streaming Replication. It's one of the Several Replication Methods that are supported by PostgreSQL.
It's for the purpose of scaling the database tier horizontally, in case your application is doing more reads than writes, and hopefully can send these read requests to the Hot-Standby Server. Also, for the purpose of having another backup of your data.
Your Standby Server can be promoted to a Primary Server at any moment, in case of the failure of the original Primary Database Server. But that is something I haven't got into myself, and I will not show it in this post.
With Streaming Replication, all the data of the database is replicated. All database, tables and users for example. You don't have a choice on what to replicate, and what to not to replicate. If you want this functionality, maybe you should look into Logical Replication which I am considering covering in another post myself.
It took me sometime to figure out how to do Streaming Replication myself, simply because most of the popular tutorials online cover PostgreSQL 9.X, and the configuration has changed on the way to PostgreSQL 13. In another word, the steps have been simplified. And that's what I am covering here. The reference [4] basically helped me to find up-to-date instructions, on how to do this on PostgreSQL 13.
Note: I will keep updating this post with more relevant information about Streaming Replication in PostgreSQL 13. But at the moment, this post acts as a reminder or notes sheet for myself at least. But I hope you find it helpful as well.
In case you think there is something wrong, or I can improve something, please reach out to me on Twitter @OmarQunsul.
Our Setup
We will need two EC2 Ubuntu Servers, on the same network. Preferably they can connect to each other using some Private IP addresses. They don't need to have IP addresses exposed to the Internet, if you want to connect to them using some PNAT Server.
We will refer to the Primary Server IP address with Primary IP, and the Standby Server by Standby IP.
Steps
- Install PostgreSQL 13 on both servers using the steps I showed in this previous post. You don't have to create a database / user. But if you want to do so, only do this on the Primary Server. then turn of the postgresql service on both of the database servers using the command.
sudo service postgresql stopPreparing the Primary Server
Add a replication user to your postgreSQL server, using your superuser postgres. In my example, the password is obviously pass.
CREATE ROLE replication WITH REPLICATION PASSWORD 'pass' LOGINThen modify the file /etc/postgres/13/main/postgresql.conf, and make sure you enable the following options.
listen_addresses = '127.0.0.1,172.31.36.195'
wal_level=replicaUsually this file is filled with commented-out configurations, that default to some value.
listen_addresses usually defaults to localhost, which means that the PostgreSQL server is only listening to connections to local applications, running on the same machine. I modified it by adding both the localhost (aka 127.0.0.1) and the private IP of the Primary Database Server. In this case it is 172.31.36.195
If you want your PostgreSQL server to be accessible to all the Network Interfaces (not recommended on Production) you can set it like this
listen_addresses = '*'Then modify the configuration file /etc/postgres/13/main/pg_hba.conf file to include (at the end) this line
host replication replication 172.31.32.170/32 md5In my case, the IP address 172.31.32.170 is the Private IP address of the Standby Database Server.
After doing this, go ahead and start the postgresql service again.
sudo service postgresql startPreparing the Standby Server
Double check that the PostgreSQL service is stopped, as indicated in the first step of this post.
The first thing we need to do, is to clean the data directory of PostgreSQL by renaming the existing directory to another backup directory.
sudo mv /var/lib/postgresql/13/main /var/lib/postgresql/13/main_oldThen modify the file /etc/postgres/13/main/postgresql.conf, and make sure you have this config set.
primary_conninfo = 'host=172.31.36.195 port=5432 user=replication password=pass'host in this case is the Private IP address of the Primary Server. user is the replication user that we created on the Primary Database Server.
After we cleaned up the data directory of the PostgreSQL Server, we need to reinitialize it with the data that existing on the PostgreSQL data directory of the Primary Database Server. We can use the command pg_basebackup to do this. We can do this by running this command.
sudo -u postgres pg_basebackup -h 172.31.36.195 -D /var/lib/postgresql/13/main -U replication -v -P --wal-method=stream --write-recovery-confEven though the option --write-recovery-conf should have done this already, but we need to create this file to tell PostgreSQL that we need to run it in standby mode. You can verify this on reference [4], in case this changes in future versions of PostgreSQL
sudo touch /var/lib/postgresql/13/main/standby.signalAfter doing this, your standby server should be ready to start.
sudo service postgresql startIn my previous PostgreSQL 13 Post I have shown some examples of creating and filling a table. Try to run these commands on the Primary Database Server and then query them on the Standby server.
And make sure you get this error when you run write queries on the Standby server as well
ERROR: cannot execute DELETE in a read-only transactionSynchronous Replication
Streaming Replication is asynchronous by default to make it synchonrous, you need to modify the parameter synchronous_commit in the file postgresql.conf to any of the values remote_write, on or remote_apply.
Each one of these value provides an extra level of durability, you can find all the details here in the documentation page of Write Ahead Log - Runtime Config Parameters.
This is an interesting config parameter. Because I found out I can speed up the performance of a chess website side project that I am running, by setting this value to off. Simply because I don't care much about the durability, as much as performance in this case.
Further TODO(s) for me
I need to read more about WAL Archiving and Replication Slots. Once I understand how they work, I will not hesitate to expand this post, or write about them in a separate post.
Also, I need to explore the topic of logical replication which seems to enable you to choose what to replicate, rather than replicating everything.
References
- PostgreSQL - Different Replication Solutions
- How to set up PostgreSQL for high availability and replication with Hot Standby
- Streaming Replication - PostgreSQL wiki
- Log-Shipping Standby Servers
- pg_basebackup
- Streaming Replication - The Internals of PostgreSQL
About
My name is Omar Qunsul. You can find me on Linkedin.
I write these articles mainly as a future reference for me. So I dedicate some time to make them look shiny, and share them with the public.
Homepage